Les 12 et 13 juin, c’était DevLille à Lille Grand Palais. Édition particulière à bien des égards. Entre les bouleversements de notre métier, le marché tendu, je me demandais quelle ambiance y règnerait. Et franchement, l’une des meilleures éditions pour moi, l’une des plus humaines, paradoxalement, alors que le mot IA a été prononcé à chacune des conférences. J’ai vu pas mal de conférences, je ne vais pas revenir sur toutes, mais quelques messages à faire passer.
Les Keynotes
Première keynote par Typhaine D. Typhaine s’est définie comme comédienne, metteuse en scène, et féministe. Sa keynote était vraiment originale, usant d’une langue de son invention, la « féminine universelle », en féminisant tous les mots. Par ce biais, elle montre que la langue français d’aujourd’hui est le fruit de choix historiques, symboles d’une volonté d’oppression. L’approche était originale, et secoue.
La deuxième keynote, le vendredi, a été tenue par Julien Vidal. Julien, lui, se définit comme « Écologiste ». Il pose alors la question de ce qui nous vient en tête quand on pense à un écologiste. Dans l’assemblée, spontanément, on a entendu « anxiété », « contrainte »… Et pas grand chose d’enthousiasmant. C’est justement ce à quoi travaille quotidiennement Julien. Il est venu nous parler de son mouvement, les 2030 Glorieuses. Le but est de réfléchir à ce qui nous rendrait heureux, et de savoir comment lier ça aux limites planétaires, et d’arrêter de lier écologie à quelque chose de forcément négatif.
Ces deux keynotes n’avaient pas grand chose de technique, bien que les thématiques soient plutôt simples à raccrocher à notre quotidien de professionnels de la tech. Mais prendre 30min pour écouter des choses dont on n’a pas l’habitude, ça fait du bien, dans l’économie de l’attention que l’on connait bien. Alors merci de nous programmer (voir imposer) ces Keynotes. Cela demande du courage, je remercie l’équipe du Devlille et en particulier Fanny d’oser faire ça.
Les Confs
Comme tous les ans, le DevLille publie toutes les vidéos sur youtube, et ce en quelques jours. Suis admiratif du travail, bravo à l’équipe de captation ! Vous trouverez aussi les photos ici. Pour ma part j’ai assisté à une dizaine de conférences. J’avais à cœur de chercher un peu les tendances du moment et sans surprise, je n’ai pas assisté à une seule conférence sans que « Intelligence Artificielle » ne soit prononcé. Tout simplement bouleversant, bien éloigné de la simple hype.
La plus symptomatique de ce phénomène, c’est peut-être la conférence de Greg Lhotellier : « L’avenir des développeurs et des développeuses » (non publiée sur Youtube). Cette conférence, en plus d’avoir fait salle comble, a parfaitement reflété les inquiétudes du moment. Pour l’intervenant, on est passé d’un domaine en pénurie de professionnel.e.s, à un domaine saturé, et ça ne sera pas sans conséquence. Comment se démarquer? Par la spécialisation, le réseautage, et le dépassement de fonction. Au delà de la conférence, il y a eu pas mal d’échanges sur le temps des questions / réponses. Une question m’a interpellé, on a sous entendu qu’il serait peut-être temps pour la profession de se structurer un peu plus, et de se syndicaliser. Et pourquoi pas…
Deuxième conférence que j’ai apprécié, celle de Montaine Marteau, « La santé a-t-elle peur du cloud ?« . Montaine a une approche vraiment sympa, parlant du quotidien des praticiens hospitaliers et de la difficulté à recueillir de l’information exploitable pour la recherche scientifique. Que cela soit pour des questions de RGPD, du fait que les patients ne comprennent jamais vraiment ce qu’ils acceptent, du fait qu’il est très dur d’anonymiser des données médicales, et que dans tous les cas la normalisation des données reste un enfer. Si vous avez traité un jour des tableurs saisis par plusieurs personnes, avec des dates ou des unités, vous savez de quoi je parle, rien ne sera jamais écrit 2 fois de la même manière ! Bref, héberger, sécuriser, normaliser et exploiter les données médicales est un challenge métier et technique vraiment passionnant. Mon épouse faisant de la recherche dans un CHU, cette présentation m’a particulièrement parlé !
Dans les autres conférences, quelques félicitations pèle mêle…
- Aurélien Allienne qui a présenté « La GenAI au service du Retail« . Le retail, c’est le premier employeur de la région, et Aurélien nous projette dans toutes ces nouvelles fonctionnalités qui devraient envahir notre façon de faire pour la vente en ligne ou la gestion magasin.
- Olivier Wulveryck pour « Le Model Context Protocol : Les APIs du Futur pour le Développement d’Agents Autonomes« . MCP est devenu un standard en quelques mois, le protocole là pour étendre les possibilités de son LLM. Olivier est un speaker exceptionnel, et cette conférence a été plébiscitée. A ne pas rater.
- Audrey Wech pour « Développer une application mobile avec React Native : pourquoi Expo change la donne ?« . Sujet qui me touche particulièrement, puisque je l’ai vécu de l’intérieur. Audrey est développeuse chez Karnott. Du haut de ses jeunes années d’expérience, elle m’a convaincu de migrer notre application mobile de React Native à Expo. Puis, après être allé au bout de cette migration, elle s’est dit que faire un retour d’expérience avait de la valeur, et s’est donc inscrite au Ch’ti Tremplin 2025, où elle a été sélectionnée pour participer au Devlille (à juste titre, le rex est vraiment quali). Bref, bravo Audrey. 💪
La conf de debrief
Quand le CFP a ouvert, j’ai discuté avec l’équipe organisatrice de l’opportunité d’enregistrer un épisode de l’EstamiTech en clôture, pour débriefer de la conf, avec pour inspiration ce que peuvent faire les Cast Codeurs à chaque Devoxx France. Ils ont gentiment accepté, me proposant un des amphis… Mais plus l’événement approchait, et moins je me sentais à l’aise avec l’idée d’avoir uniquement quelques personnes sur scène donnant leur version du Devlille. Je voulais quelque chose de plus participatif avec le public. J’ai donc essayé de suivre une trame reprenant quelques unes de mes préoccupations actuelles, et j’ai demandé au public d’y répondre, à l’aide de Slido, et de plusieurs micros circulant dans la salle… En complément, Fanny a proposé au Ch’ti JUG de sponsoriser le moment avec quelques boissons, chose qu’ils ont tout de suite et gentiment accepté. Alors hop, petite ambiance estaminet…

- Réflexe de Dev.e. Comment on trouve des réponses à nos blocages du quotidien ?
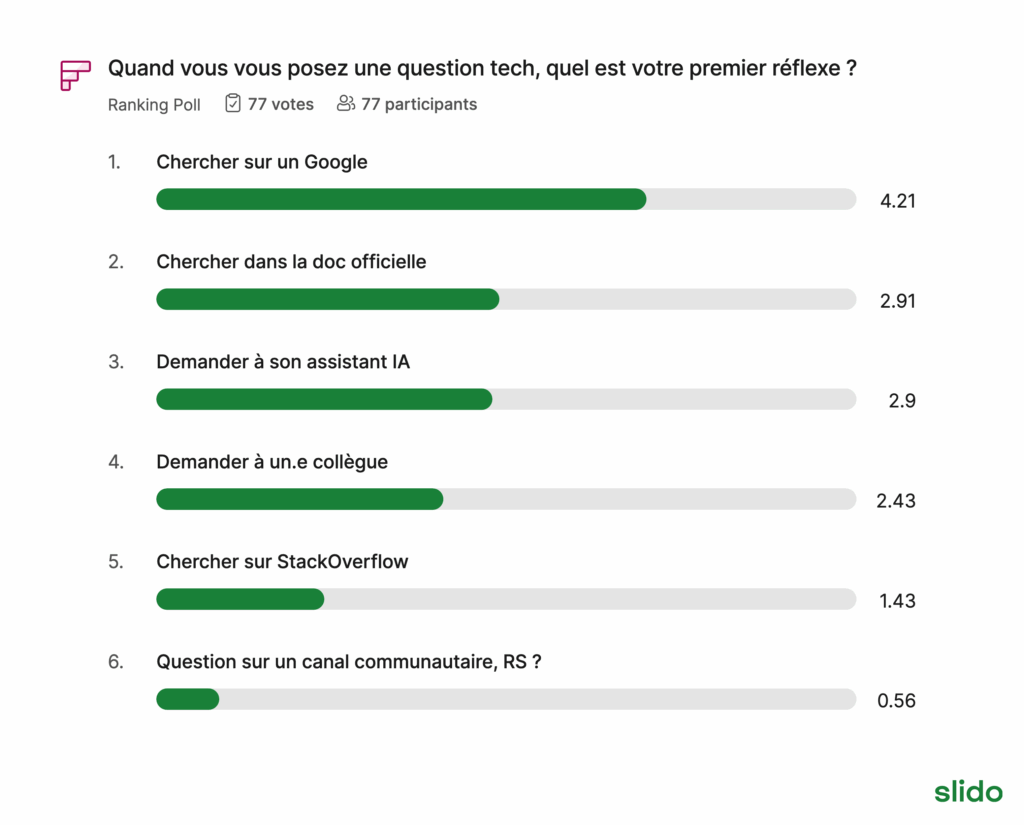
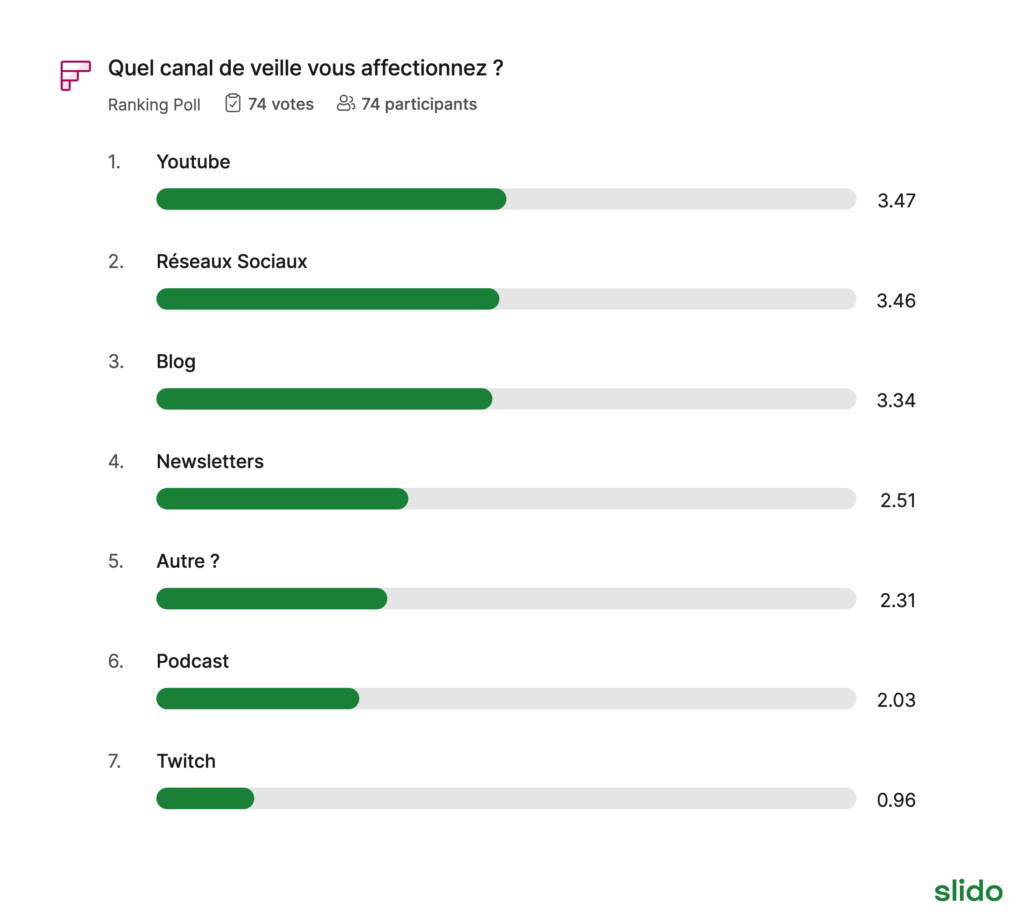
- Comment on fait de la veille en 2025 ?
- Qu’est ce qu’une bonne conf ? Avec la participations des gagnants du tremplin…
- Vote pour sa conf préférée… Avec en top 3, en vote du public :
- « Le Model Context Protocol : Les APIs du Futur pour le Développement d’Agents Autonomes » par Olivier Wulveryck dont je parle ci-dessus
- « Code Case : les méthodes de la crim’ adaptées au code! » par Sylvain Coudert
- « Le libre et l’open source » par Marie Dubremetz
Le Devlille est sur deux jours, termine le vendredi avec une dernière conf à 16h30, et il faut avouer qu’après 16h il n’y a déjà plus grand monde. Les stands sont démontés, et tout le monde part en week-end bien fatigué. Alors débriefer entre 17h30 et 18h30, ça aurait pu être un petit flop. Mais au final, on s’est retrouvé avec une petite centaine de personnes (102 d’après Slido), et dans une excellente ambiance (il faut dire que les ami.e.s étaient là, au soutien). L’exercice de la conf participative n’est pas simple. Il faut garder le rythme sur des sujets intéressants, et le plus dur : avoir une bonne gestion du temps, ne maitrisant pas trop le temps de chacune des interventions. J’ai trouvé ça bien plus dur qu’une simple conférence maitrisée de A à Z. En tout cas, tout le monde avait envie de participer, et je retiendrai que tous nos assistants IA ne tariront pas l’envie d’échanger entre techs. Je suis sorti de là rassuré sur l’avenir de notre métier… L’idée de faire un podcast ou une chaine DevTherapy en libre antenne a même germé. J’ai au final passé un excellent moment 🙂
Si vous souhaitez entendre nos débats, le replay est disponible ici
DevLille, à l’an prochain bien sûr.

L.B.